湾区同学技术沙龙
(Bay Area) An introduction of Analytics Zoo and how to use it at Uber
21 July 2019
1:30PM ~ 5:00PM, 7/21/2019, Sunday
Registration
- Registration link: tech-meetup-07-21-2019.eventbrite.com/
- Event link: (Bay Area) An introduction of Analytics Zoo and how to use it at Uber
Join tech-meetup community:
- LinkedIn group: www.linkedin.com/groups/8362423
- 微信群/Google group: tech-meetup.com/groups
Event Info
- Time: 1:30PM ~ 5:00PM, 7/21/2019, Sunday
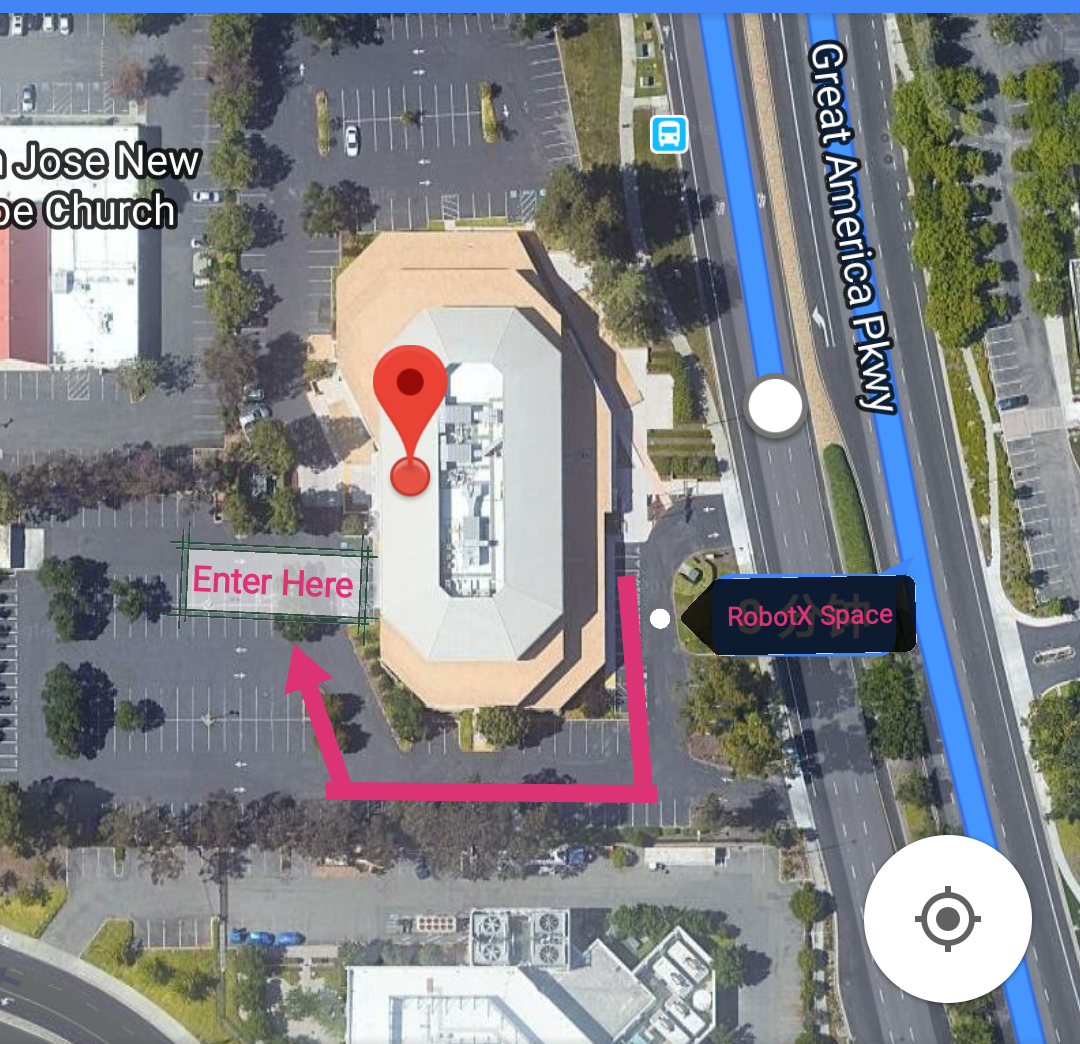
- Location: 1st Floor Pitch Room, 4500 Great America Parkway, Santa Clara 95054 (ZGC Innovation Center)
- Language: Chinese
Agenda
- 1:30pm - 2:00pm: Reception and social time
- 2:00pm - 3:20pm: Deep Learning on Sensor Data with Analytics Zoo at Uber + Q&A
- 3:20pm - 3:30pm: Break
- 3:30pm - 4:50pm: Analytics Zoo Introduction + Q&A
- 4:50pm - 5:10pm: offline networking
Talk 1: Deep Learning on Sensor Data with Analytics Zoo at Uber(Speaker: Lucinda Zhao)
Uber processes TBs of sensor data daily to build better products. For example crash detection with which operators can reach out to drivers who are detected going through accidents to provide prompt guidance and support. Sensor data is one important input to such applications.
Sensor data is ideal for Deep Learning. However, overhead for DL dev and productionisation is large -- most frameworks focus only on model training (forward/backward propagation) whereas data ingestion, model integration, pipeline management etc are left behind. Those steps may end up eating up big chunk of dev cycle. AnalyticsZoo fills in the missing pieces.
In this talk we will provide overall experience feedback for DL on large-scale business data with AnalyticsZoo from users’ point of view: how the workflow looks like, how AZ helps boost dev/productionisation efficiency in DL and what are the potential concerns. Overall it’s definitely a framework worth onboarding when live in the Hadoop-Spark BigData-DL ecosystem.
Lucinda(Luyu) Zhao: ML engineer at Sensor Intelligence team of Uber. Joined Uber in 2015 she has worked on various projects utilizing sensor data to provide inferences and insights. Before Uber she worked at Qualcomm designing baseband signal processing algorithm and architecture. She has background and production level first hand experience in big data, machine learning, wireless communication and signal processing.

Talk 2: An Introduction to Analytics Zoo: Distributed TensorFlow, Kerasand BigDLon Apache Spark (Yuhao Yang)
Analytics-Zoo是基于Apache Spark以及BigDL的开源分布式深度学习框架(https://github.com/intel-analytics/analytics-zoo)。它为Spark提供了深入学习功能的原生支持,同时为现成的使用单节点志强Xeon CPU的开源深度学习框架(如Caffe和Torch)带来了数量级的性能速度提升,并为它们提供了基于Spark架构的对深度学习任务的高效的水平扩展的能力;此外,它还允许数据科学家使用熟悉的工具(包括Python和Notebook等)来对大数据进行分布式深度学习分析。在这次演讲中,我们将演示大数据用户和数据科学家如何使用Analytics-Zoo以分布式方式对海量数据进行深度学习分析(如图像识别、对象检测、NLP等)。这可以让他们使用已有的大数据集群(例如Apache Hadoop和Spark)来作为数据存储、数据处理和挖掘、特征工程、传统的(非深度)机器学习和深度学习工作负载的统一数据分析平台。
Yuhao Yang: senior software engineer on the big data team at Intel, where he focuses on deep learning algorithms and applications—particularly distributed deep learning and machine learning solutions for fraud detection, recommendation, speech recognition, and visual perception. He’s also an active contributor to Apache Spark MLlib.

主办
- 湾区同学技术沙龙(TechM)
- ZGC Innovation Center
协办
- 硅谷新创汇
- 南京大学湾区校友会
- 东南大学硅谷校友会
- 中国科大硅谷校友会
- 北加州清华校友会
- 硅谷清华联网
- 浙江大学校友会海纳创新创业俱乐部
- 北京大学北加州校友会
- 武汉大学北加州校友会
- 吉林大学硅谷校友会会
- 复旦大学北加州校友会
- 华南理工大学美国校友会
- 北加州华中科技大学校友会
- 北京航空航天大学硅谷校友会
- 北京邮电大学北美校友会
- 上海交通大学硅谷校友会
- 兰州大学北加州校友会
- 电子科技大学硅谷校友会
- 安徽大学北美校友会
- 湖南大学北美校友会
- 湘潭大学北美校友会
- 哈工大硅谷校友会
- 中山大学海外校友联网
- 华人事业互助会
Related articles
- (Bay Area) Food Robotics AI from Scratch
- (Bay Area) Bay Area Data Infrastructure Meetup (Zilliz&RisingWave&OceanBase)
- (Bay Area) Snowflake / Databricks / OceanBase
- (Bay Area) 云端数据中台:数据编排与平台运维
- (Bay Area) Google Doc 是如何炼成的 - 深入浅出协同编辑/Deep Dive Collaborative Editing
- (Bay Area) Tensorflow.JS: Bringing Machine Learning To The Web And Beyond
- (Bay Area) Weakly Supervised Natural Language Understanding / 基于弱监督学习的自然语言理解 By Mosaix.ai
- (Bay Area) Data Extraction Revolution in Bloomberg, From Human Typing To Deep Learning Excerpting
- (Bay Area) Next-Generation AI Powered Operation System
- (Bay Area) Power Blockchain with Hardware Innovations
- (Bay Area) 区块链产业现状及技术发展(阿里巴巴技术日)
- (Bay Area) Anatomizing Blockchain through Many Views(区块链折叠)
- (Bay Area) Deep Dive of Alluxio and Google gVisor
- (Bay Area) 技术创造新商业:阿里巴巴搜索推荐&计算平台事业部硅谷开放日
- (Bay Area) Google Translate助力自然语言理解
- (Bay Area) Alibaba Tech Open Day – AI, Cloud, Infrastructure and More
- (Bay Area) 通向区块链3.0的未来之路
- (Bay Area) Alibaba New Retail / Hema Tech Day (盒马生鲜技术日)
- (Bay Area) exGoogle Leaders, leap.ai co-founders share their career stories & insights (Richard Liu, Yunkai Zhou)
- (Bay Area) Augmented Intelligence to Improve Health Care Consumer Experience
- (Bay Area) GrowingIO 湾区技术同学见面会
- (Bay Area) Alibaba Technology Forum, Stanford University
- (Bay Area) How Pinterest Perfected New User Onboarding
- (Bay Area) Tencent Tech Day - Silicon Valley
- (Bay Area) Deep dive of DeepMap (Wei Luo)
- (Bay Area) Apache Kafka: The Rise of Real-time
- (Bay Area) 苏宁机器学习平台及Buddy AI人工智能自动客服系统技术分享
- (Bay Area) JD.com Tech Day - Leverage Technology to empower business intelligence
- (Shanghai) 采用超低功耗AI技术的小MU机器人的实现与应用
- (Bay Area) Transwarp(星环科技) && DistributedLog
- (Bay Area) AI in Service robotics and Mini Robot
- (Shanghai) Google SRE如何管理数据中心
- (Bay Area) 如何用1/6000的训练数据击败深度学习——文字识别实验讨论
- (Shanghai) Twitter Heron Streaming at Scale
- (Bay Area) AI大牛谈深度学习最新进展
- (Bay Area) 新一代创新搜索技术架构讨论专场
- (Bay Area) CAINIAO Technology Forum, Silicon Valley
- (Bay Area) How to build a NewSQL database? (Qi Liu)
- (Bay Area) The Evolution of Big Data APIs in Spark (Reynold Xin)
- (Bay Area) TensorFlow: A Large-Scale Machine Learning System (Zhifeng Chen)
- (Bay Area) Ant Financial Tech Forum (2016蚂蚁金服技术湾区论坛)
- (Bay Area) Espresso: LinkedIn’s Distributed Database (Yun Sun)
- (Bay Area) Virtual Reality & Augmented Reality (Guodong Rong)
- (Bay Area) Etcd: A key-value store Open Source for Data consistency, Data persistency, Data synchronization in Distributed system (Xiang Li)
- (Bay Area) Introduction To OpenStack (Weidong Shao & Xin Wu)
- (Bay Area) A Journey of AI: from Silicon Valley to Beijing, from Big Name to Startup (Kai Yu)
- (Bay Area) Borg: Large-scale Cluster Management at Google (Xiao Zhang)
- (Bay Area) CoreOS rkt, a Container Runtime (Yifan Gu)
- (Bay Area) Spark MLlib: Past, Present and Future (Xiangrui Meng)
- (Bay Area) Cassandra: an open source distributed database (Charles Cao)
- (Bay Area) Tachyon: an open source memory-centric distributed storage system (Bin Fan / Shaoshan Liu / Haoyuan Li)
- (Bay Area) Apache Samza: a distributed stream processing framework (Yi Pan)
- (Bay Area) 大数据时代的金融服务创新 (Li Cheng)
- (Bay Area) 大数据人工智能 (Kai Yu)
- (Bay Area) Photon: Fault-tolerant and scalable joining of continuous data streams (Tianhao Qiu)
- (Bay Area) Large-scale data science and engineering with Spark (Reynold Xin)
- (Bay Area) Building a real time data platform with Apache Kafka (Jun Rao)
- (Bay Area) Kubernetes: Google’s secret weapon for Cloud computing (Dawn Chen)
- (Bay Area) Tachyon: A Reliable Memory-Centric Distributed Storage System